Header Data in Messaging
Table of Contents
Overview
A message typically has two components: a payload component and a header component. The first represents the actual message content, whereas the latter is regarded as metadata whose format is normally applicable to diverse message types. Thus, header data refers to the type of data that is typically included in a message’s header component.
The most common type of header data attributes are as follows (variable-like names are used for naming simplicity):
- consumerRequestId: a unique identifier produced by the consumer that issues the initial request.
- requestId: a unique identifier produced by the first provider in the integration layer.
- user: the consumer account’s user.
- password: the consumer account’s password or token, depending on the protocol.
The consumerRequestId and requestId attributes are correlation identifiers.
Correlation Identifier
A correlation identifier serves to uniquely identify a single message that traverses through various nodes and/or a process (usually triggered by a message).
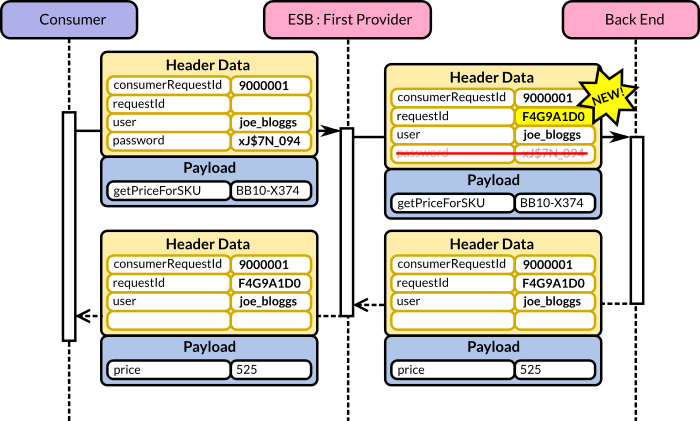
There is a substantial difference between a correlation identifier created by the initial consumer (consumerRequestId) and that created by the first provider in the integration layer that accepts the request (requestId).
consumerRequestId
This attribute is populated by the consumer that creates the initial request. The advantages of asking consumers to provide such an identifier are as follows:
- Troubleshooting: if the integration infrastructure is unable to return a message back to the consumer, the consumer’s owners still need to be able to make an inquiry about the precise message that “failed”.
- Idempotency: The identifier can be used to signify that the intended invocation should occur only once—irrespective of the number of invocations. For example, in the case in which the consumer has to retry an operation after receiving no response.
The main drawback concerning a consumer-generated correlation identifier is that the integration layer cannot guarantee that the consumer will populate the attribute with semantically correct values. For example, in the case of an idempotent operation, the developers may inadvertently populate the attribute with a new value.
requestId
This correlation identifier is created by the first provider in the integration layer that accepts the consumer’s invocation. This is typically the same provider that implements the authentication & authorisation capabilities—most likely an ESB or an Access Gateway/XML appliance.
The objective of the requestId is to uniquely identify the request (and matching response) as it travels throughout the integration infrastructure and back-end systems. Unless the precise context is specified, the term correlation identifier refers to this attribute.
Consumer’s Credentials
The consumer credentials are usually set by the consumer itself and then evaluated by the first provider in the integration layer that implements the authentication & authorisation capabilities. Such a provider may then remove such attributes or alter them.
user
This is typically an identifier recognised by an Identity Provider that the authorisation and authentication provider uses to validate the account. This attribute is normally passed down the integration and back-end chain since it may be helpful for systems that need to perform specific role-based authorisation.
password
In simpler protocols, such as HTTP Basic Access Authentication (or the simple WS-Security token profile), the consumer sends the user and password as part of the request. When this is the case, the authenticating provider will commonly remove (or set to blank) the password attribute before passing the message to the next node in the chain.
Alternatively, in a token-based system, the password would contain a token value which is valid for a limited time. In order for this scheme to work, the consumer needs to perform a separate request with a username and password in order to authenticate with the provider and obtain the token in the first place.
Other Attributes
These are other attributes that may be used as header data:
- originatorIP: the consumer’s IP address.
- channelId: a channel identifier such as Web, App, IVR, Kiosk, etc. This may be populated by the first provider by drawing extra information from the identity provider.
- processId: whenever a long–running process may spawn multiple requests and responses that need to be tracked independently from the first message that triggered the process.
Header Data in SOAP
Our discussion was with the abstract conception of header data attributes. However, in SOAP, each of the WS-* specifications (WS-Coordination, WS-BPEL, WS-Addressing, WS-ReliableMessaging) have their own correlation attributes; they do not need to be implemented in a bespoke fashion.