Command and Query Responsibility Segregation (CQRS) Pattern
 Learning CQRS using Haskell.
Learning CQRS using Haskell.
Table of Contents
Introduction
The Command and Query Responsibility Segregation (CQRS) Pattern is described by Homer et al. (2014, 42) and Fowler (2011), based on the work by Young (2010), as a solution to the problems1 that are inherent to the Create, Read, Update and Delete (CRUD)2 approach to data handling.
Unlike many patterns that answer to general business or engineering problems, the CQRS pattern is an alternative to the another pattern, CRUD, due its various claimed shortcomings. In more concrete terms, it is CRUD in the way it is commonly implemented in Object-Oriented Languages (OOP), involving the use of Data Transfer Objects (DTOs) (Homer et al. 2014, 42) and Object Relational Mapping (ORM) technology (Young 2010, 6) such as Hibernate3 or Entity Framework4.
In this article, we will examine whether the problem identified by the pattern as well as the suggested solution is applicable to a functional programming language like Haskell. For simplicity, we ignore Event Sourcing (Fowler 2005) as the default “backend” implementation for CQRS.
Problem
Functional Problems
This pattern is based on the shortcomings that emerge from what Young (2010, 2) calls a “Stereotypical Architecture” which typically implements the CRUD paradigm using Data Transfer Objects (DTOs) to represent both retrieved data as well as data to be changed.
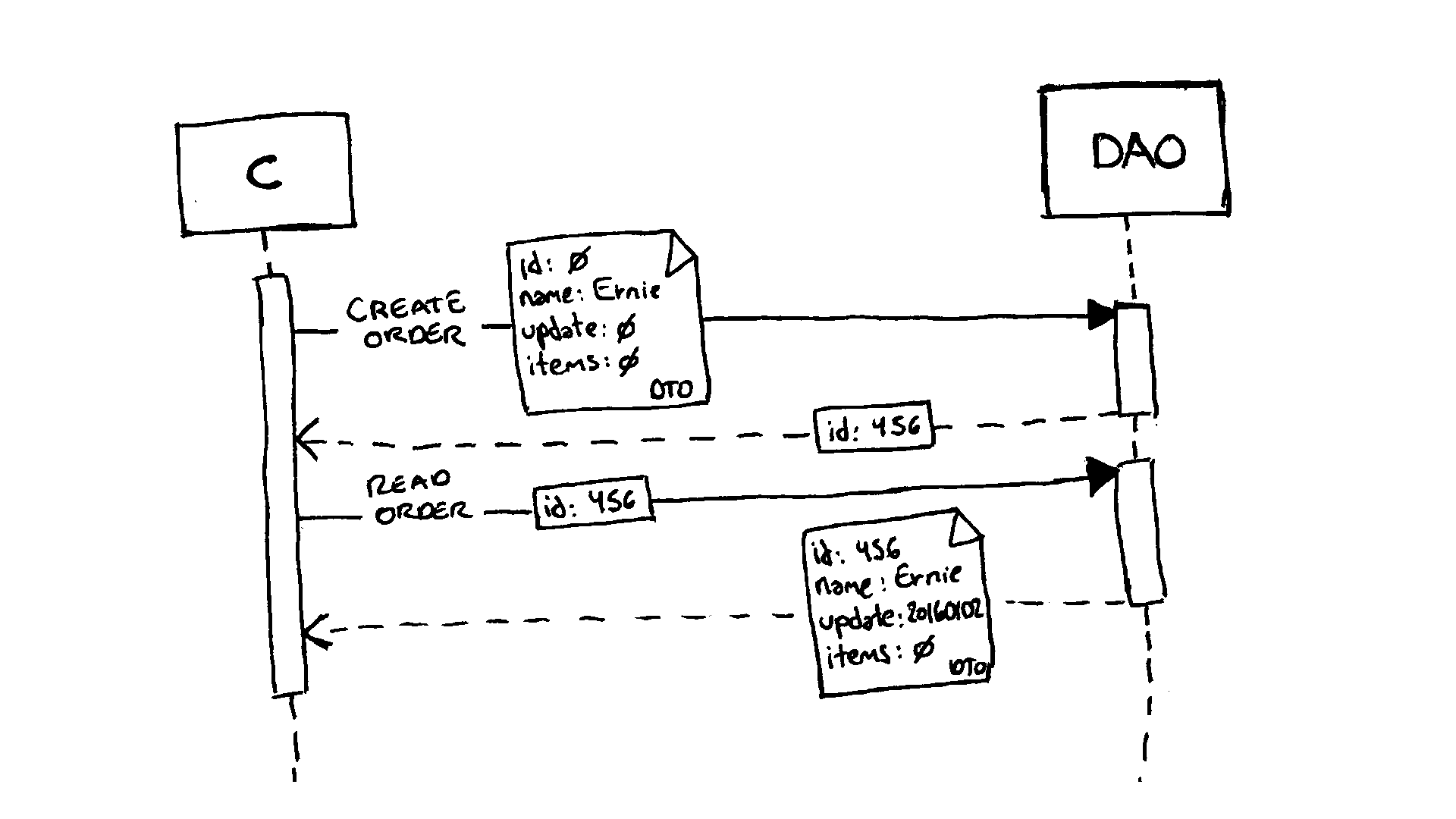
The main issue, though, is conceptual (the use of a single model for both read and write operations) and not necessarily exclusive to imperative OOP languages. Let’s consider an example by representing an order consisting of line items using the record syntax in Haskell.
1type OrderId = Int
2type Date = String
3type ItemId = Int
4type Name = String
5type Description = String
6type Qty = Int
7type Price = Float
8
9data Order = Order {
10 orderId :: Maybe OrderId
11 ,lastUpdate :: Maybe Date
12 ,customerName :: Name
13 ,lineItems :: [LineItem]
14} deriving (Show)
15
16data LineItem = LineItem {
17 parentOrderId :: Maybe OrderId
18 ,itemId :: Maybe ItemId
19 ,description :: Description
20 ,qty :: Qty
21 ,price :: Price
22} deriving (Show)
The idea under the CRUD/DTO metaphor is that we can “consistently” manipulate the data using the same entity representation—“DTO up/down interaction” (Young 2010, 4)—for both read and write actions so we have a series of functions that implement the CRUD verbs against the above defined data types:
1orderCreate :: Order -> IO OrderId
2orderRead :: OrderId -> IO Order
3orderUpdate :: Order -> IO ()
4orderDelete :: OrderId -> IO ()
5
6lineItemCreate :: LineItem -> IO ItemId
7lineItemRead :: ItemId -> IO LineItem
8lineItemUpdate :: LineItem -> IO ()
9lineItemDelete :: ItemId -> IO ()
So far so good. Let’s look at the case of reading an existing order, say order#456:
1-- Read Code
2order <- orderRead 456
3putStr "Order #"
4putStrLn $ case orderId order of
5 Just orderId -> show $ orderId
6 Nothing -> "Order Id missing"
7putStr "Last Updated: "
8putStrLn $ case lastUpdate order of
9 Just date -> date
10 Nothing -> "Never updated"
11putStrLn $ concat ["Customer: ",customerName order]
12putStr "Line Items: "
13mapM_ print $ lineItems order
Why is the code so verbose? Because the orderId and lastUpdate
fields are of type Maybe since they may be potentially empty. One can
argue that the orderRead function should guarantee that an Order
value is always “correctly” populated; an exception should be thrown if
this not the case. Likewise, we already know the value of orderId
(456).
The point is, though, that simply applying fromJust to an Order’s
field, in the belief that it was generated by the right function, is an
accident waiting to happen. Thus, bullet-proof code should contemplate
the possibility that the value under consideration may not have
originated from the correct function.
If we now look at the act of creating a new order, we will find new issues. The first has to do with consistency. If entities are treated atomically, then we need to perform our CRUD actions within some sort of transactional context. For instance:
1-- Write Code
2transactionWrapper $ do
3 let order = Order {
4 orderId = Nothing
5 ,lastUpdate = Nothing
6 ,customerName = "Ernie"
7 ,lineItems = []
8 }
9 orderId <- orderCreate order
10 let item1 = LineItem {
11 parentOrderId = Just orderId
12 ,itemId = Nothing
13 ,description = "Garlic Bread"
14 ,qty = 2
15 ,price = 3.5
16 }
17 itemId <- lineItemCreate item1
18 return ()
In the above example, we first create an Order value and obtain its
orderId, and then use it to create a LineItem value separately. Note
in this case, unlike that of read code we had contemplated before, we
have to set the orderId and lastUpdate fields to Nothing. The
entire procedure is wrapped by the transactionWrapper function that
creates the appropriate context for the underlying data store.
This is just a way of implementing the creation of a complete order.
Another possibility is to populate Order with all its children
LineItem values so that both are persisted as part of a single create
action:
1-- Write Code (Alternative version)
2let item1 = LineItem {
3 parentOrderId = Nothing
4 ,itemId = Nothing
5 ,description = "Garlic Bread"
6 ,qty = 2
7 ,price = 3.5
8 }
9let order = Order {
10 orderId = Nothing
11 ,customerName = "Ernie"
12 ,lastUpdate = Nothing
13 ,lineItems = [item1]
14 }
15orderCreate order
Note in the above code that the parentOrderId is now set to Nothing as
opposed to the previous version.
In a nutshell, the Order and LineItem values must be handled in
different ways depending on the context. This situation may lead to bugs
and unintended behaviour. In the case of the Order type in particular,
we can use the following table to see how different values are expected
under different contexts:
| Context | orderId |
lastUpdate |
lineItems |
|---|---|---|---|
| Create | Nothing |
Nothing |
[] |
| Read | Just x |
Just x |
[], ..., [x:n] |
| Update | Just x |
Nothing |
[], ..., [x:n] |
| Delete | - | - | - |
This is, in a nutshell, the main issue surrounding the CRUD/DTO paradigm; however, this example may not be sufficient to discredit it yet. Let’s look at a more real-world use case in which we are asked to produce a report of customer names and their purchased items based on a given price. Let’s say that the manager wants to know who are the “stingy” customers who buy items priced at £3.50.
For example:
1> stingyCustomersReport 3.50
2Customer Name: Ernie - Item: Garlic Bread
3Customer Name: Ernie - Item: Mozzarella Sticks
4Customer Name: Giovanna - Item: Potato Wedges
By trying to abide to the CRUD/DTO metaphor, we could produce a list of orders and populate just the fields that are relevant to the report:
1...
2 [Order {
3 orderId = Nothing
4 ,lastUpdate = Nothing
5 ,customerName = "Ernie"
6 ,lineItems = [LineItem {
7 parentOrderId = Nothing
8 ,itemId = Nothing
9 ,description = "Garlic Bread"
10 ,qty = 0
11 ,price = 0
12 }
13 ]
14 }
15...
In order to produce the above report, a function is required to
“navigate” the result produced by readPrice.
1stingyCustomersReport :: Price -> IO ()
2stingyCustomersReport price = do
3 orders <- readByPrice price
4 mapM_ (\order -> do
5 putStr "Customer Name: "
6 putStr $ customerName order
7 putStr " - Item: "
8 case length (lineItems order) of
9 1 -> putStrLn $ description ((lineItems order)!!0)
10 0 -> putStrLn "No items found"
11 _ -> putStrLn "Multiple items found"
12 ) orders
Again, we come across verbose code for something which should be fairly
trivial. The above code iterates through a list of orders and extracts
the customer’s name and the item’s description from each LineItem
value associated with an Order value.
Under this new context, the cardinality of lineItems is exactly 1,
since exactly one line item per customer record is being used to
associate a customer name with an item description. This results in a
new context for the Order entity, so we add ReadByPrice to the context
table we have recently introduced:
| Context | orderId |
lastUpdate |
lineItems |
|---|---|---|---|
| Create | Nothing |
Nothing |
[] |
| Read | Just x |
Just x |
[], ..., [x:n] |
| Update | Just x |
Nothing |
[], ..., [x:n] |
| Delete | - | - | - |
| ReadByPrice | Nothing |
Nothing |
[x] |
Let’s suppose that the manager asks us to add the suffix “Stingy” to the first customer of the list returned by £3.50 and that we want to implement the requirement by leveraging our CRUD/DTO superpowers:
1orders <- readByPrice 3.50
2case orders of
3 (o:_) -> orderUpdate o {
4 customerName = (customerName o) ++ " Stingy"
5 }
6 _ -> putStrLn "No orders found"
Because different invariants hold for Order under different contexts,
the above will fail. For instance, the orderUpdate function expects
orderId to be populated. To make the above code work, we would need to
choose, broadly speaking, one of the following two strategies:
-
Populate the
Ordervalue with all the fields that make it compatible with theCreatecontext. This can only work ifLineItemvalues are updated independently fromOrdersince thereadByPricefunction only returns oneLineItemvalue perOrdervalue. -
Modify
readByPriceso that it returns at leastorderIdand then obtain a new completeOrdervalue using theorderReadfunction.
For the second strategy, this is what the code would like like—please
note the dangerous fromJust application on orderId and how easy it
is to mistake o' (primed version) for o.
1 orders <- readByPrice 3.50
2 case orders of
3 (o:_) -> do o' <- orderRead (fromJust $ orderId o)
4 orderUpdate o' {
5 customerName = (customerName o) ++ " Stingy"
6 }
7 _ -> putStrLn "No orders found"
In conclusion, reusing DTOs to create views or projections, like in the
case of readByPrice, further aggravates the problems that the CRUD/DTO
paradigm intrinsically exhibits. Homer et al. (2014, 43) also note that
the CRUD approach “can make managing security and permissions more
cumbersome because each entity is subject to both read and write
operations, which might inadvertently expose data in the wrong context.”
Non-Functional Problems
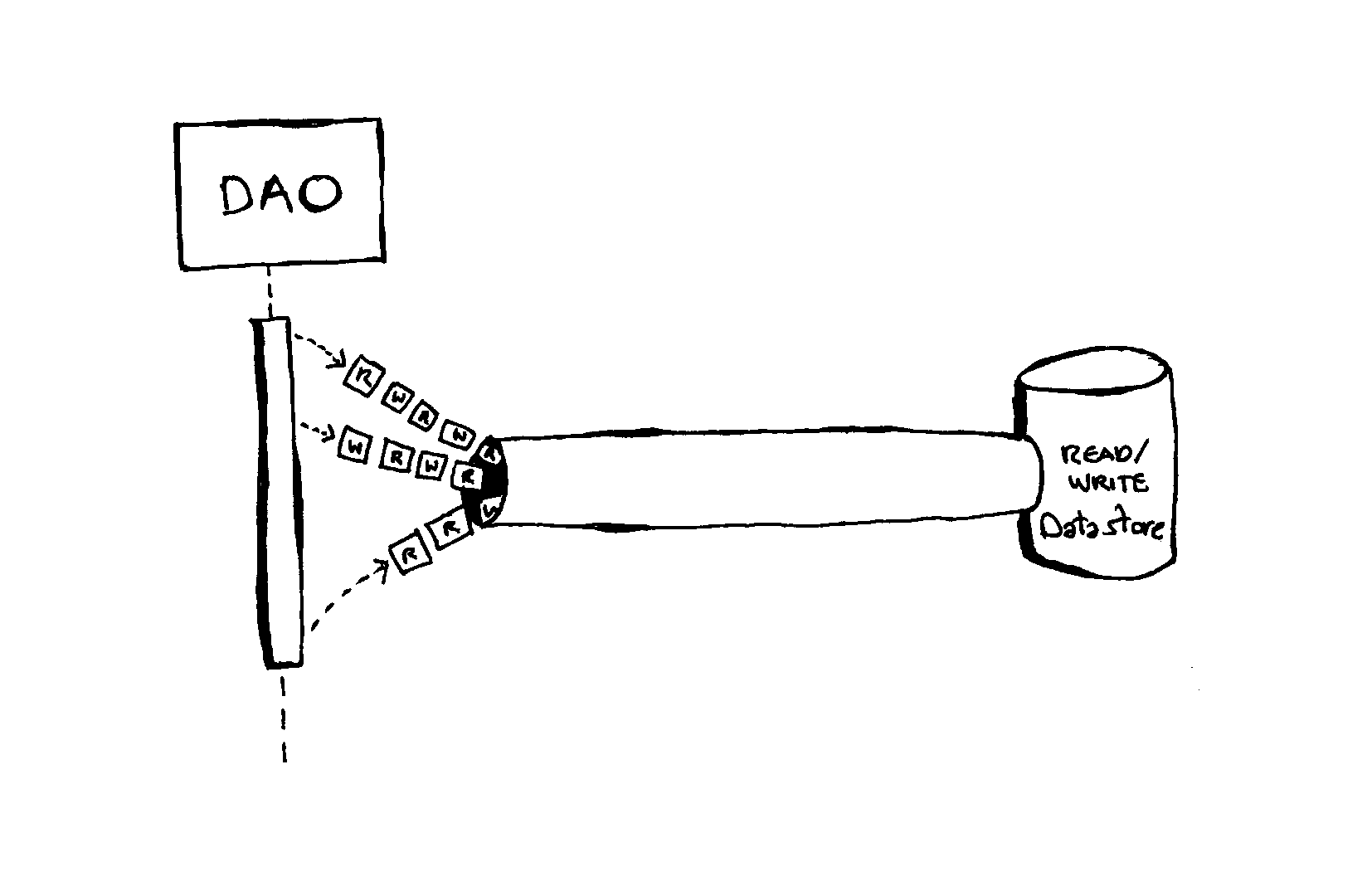
The CRUD/DTO strategy does not necessarily dictate an underlying implementation, but if the implementation consists of a monolithic data access layer (for example, Hibernate in Java or Persistent5 in Haskell) that points to a single physical data store (for example, MySQL), then the following issues may arise:
-
Data access contention: when multiple actors operate in parallel on the same data and different locking strategies are employed.
-
Problematic one-size fits all optimisation: both read and write operations are impacted by the same performance constraints since they both share the same physical access pipe.
Solution
Functional
As the pattern’s name suggests, the solution is to segregate the write (command) from the read (query) operations.
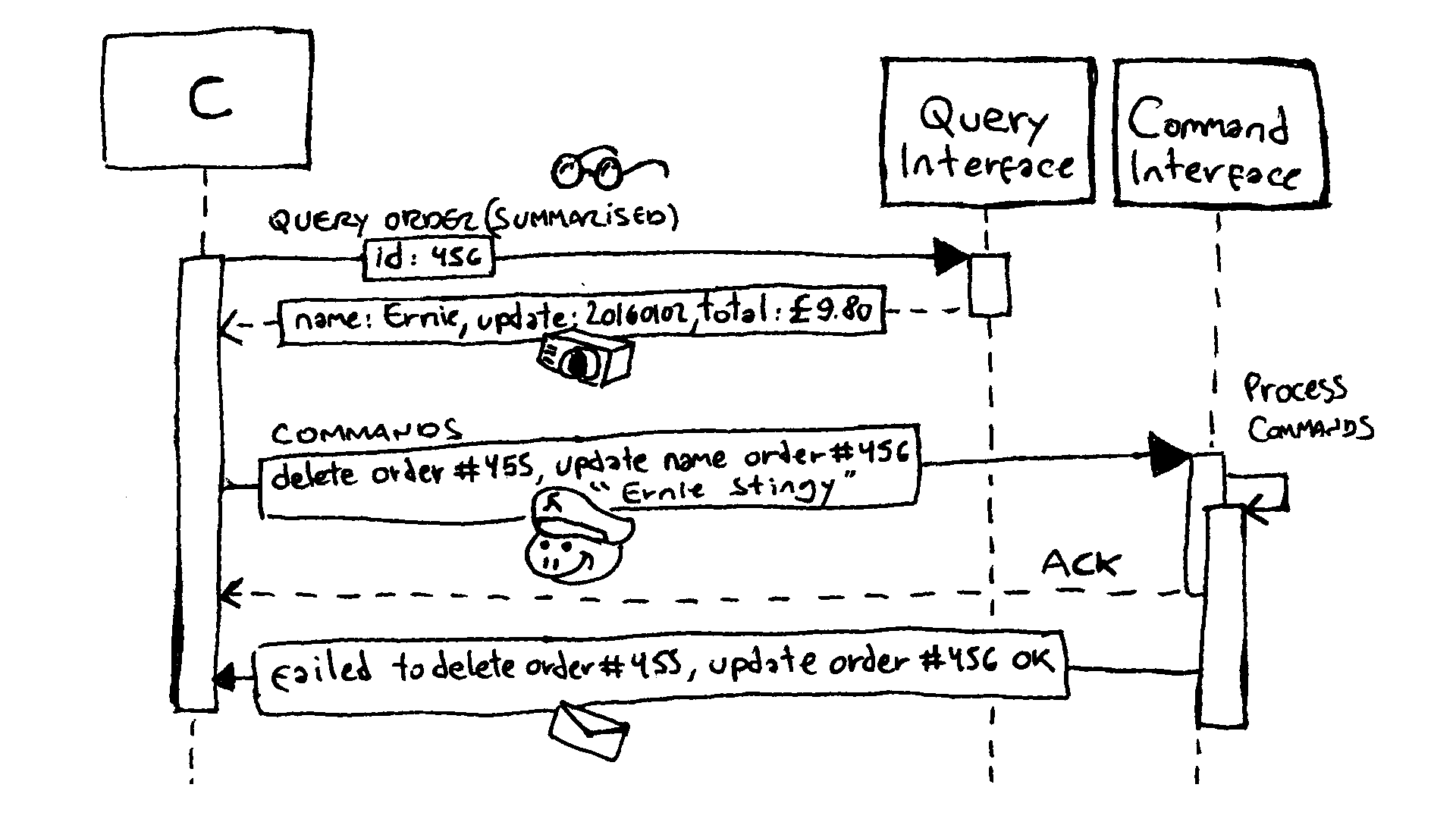
Let’s start with the query functions. In the below example we return
views as tuples which make it easier to create ad-hoc projections. For
example, the orderQuerySummarised function returns a succinct summary
in which the line items have been summed to produce a total price
whereas orderQueryFull returns the full order with a list of line
items.
1type Total = Price
2
3orderQuerySummarised :: OrderId
4 -> IO (Name,Date,Total)
5orderQueryFull :: OrderId
6 -> IO (Name,Date,Total
7 ,[(Description,Qty,Price)]
8 )
9orderQueryLineItems :: OrderId
10 -> IO (
11 [(ItemId,Description,Qty,Price)]
12 )
13orderQueryItem :: ItemId
14 -> IO (Description,Qty,Price)
15orderQueryByPrice :: Price
16 -> IO ([(OrderId,Name,Description)])
We can immediately see how this model is more efficient than the CRUD one since it eliminates the redundancies associated with DTOs. However, Homer et al. (2014, 43) note: “one disadvantage is that, unlike CRUD designs, CQRS code cannot automatically be generated by using scaffold mechanisms”. Indeed, a framework like Persistence, could not anticipate what specific queries the programmer had in mind.
We now turn our attention to the Command aspect. The idea here is that we have specialised commands to alter the persisted state at the right level of granularity and in a way that is independent from the read (query) model:
1data OrderCommand =
2 OrderCreate Name [(Description,Qty,Price)]
3 | OrderUpdateName OrderId Name
4 | OrderUpdateFull OrderId Name [(Description,Qty,Price)]
5 | OrderUpdateItem OrderId ItemId Description Qty Price
6 | OrderDelete OrderId
7 deriving (Show)
For example, the OrderUpdateName command only changes the order’s
customer name whereas OrderUpdateFull also replaces the order’s line
items.
An interesting property of the command approach is that we can easily process a list of commands rather than creating a specific function for each command since they are disconnected from the query model.
1orderCommand :: [OrderCommand] -> IO [OrderEvent]
Note: An ideal CQRS implementation would return the commands' events in an asynchronous, non-blocking fashion. This model simply aims to illustrate the pattern’s functional implication. Note also that these events represent the commands’ outcomes and are not to be confused with events for the purpose of implementing the Event Sourcing pattern.
These are the possible events that may arise from sending the defined commands:
1data OrderEvent =
2 OrderCreated OrderId
3 | OrderCreateFailed Name
4 | OrderUpdated OrderId String
5 | OrderUpdateFailed OrderId
6 | OrderItemUpdated OrderId ItemId
7 | OrderItemUpdateFailed OrderId ItemId
8 | OrderDeleted OrderId
9 | OrderDeleteFailed OrderId
10 deriving (Show)
Now that we are equipped with our CQRS version of our order handling framework, let’s reimplement the stingy customers report requirement. However, since we had spent too much time coding, the manager has just come up a new requirement:
“By the way, if you find Herbert among the stingy customers, please delete his orders! He is my naughty cousin who has been ordering low priced starters just to annoy me.”
Fair enough. We first get a list of stingy customers by applying the
orderQueryByPrice function which returns a clean list of tuples
(OrderId,Name,Description) from orderQueryByPrice. Right after, we
write a function called managerRequest which implements the
requirement: if the name is “Herbert”, we issue an OrderDelete
command, otherwise, we just append the word “Stingy” to the customer’s
name:
1stingyCustomerList <- orderQueryByPrice 3.50
2let managerRequest (orderId,name,_) =
3 case name of
4 "Herbert" -> OrderDelete orderId
5 _ -> OrderUpdateName orderId
6 (name ++ " Stingy")
All we have to do now is simply apply the function managerRequest to
each tuple in stingyCustomerList and pass the result (which is a list
of commands) to the orderCommand function:
1events <- orderCommand $
2 map managerRequest stingyCustomerList
That’s it. The consumer code is actually less verbose and more
meaningful than the CRUD/DTO version we had recently exemplified. But
what about errors? We can examine the events list and produce a report
as follows:
1let report = map
2 (\event -> case event of
3 OrderDeleteFailed orderId -> "Could not delete: "
4 ++ show orderId
5 OrderUpdateFailed orderId -> "Could not update: "
6 ++ show orderId
7 ) events
8case report of
9 [] -> putStrLn "Success!"
10 xs -> mapM_ putStrLn report
Non-Functional
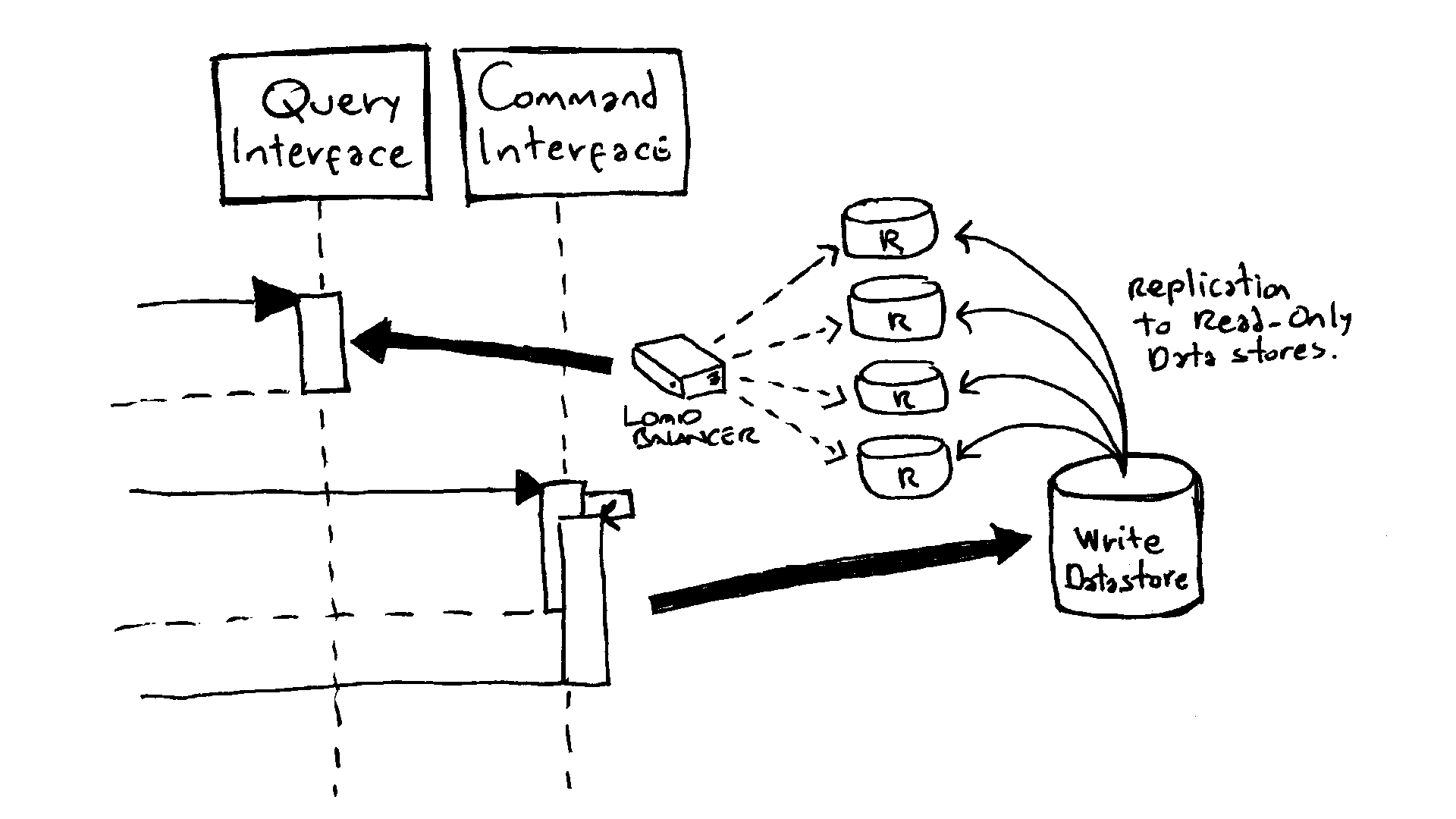
The CQRS pattern not only suggests that data should be handled using a different set of application-level functions but that it also should be segregated in terms of different read and write physical stores (Homer et al. 2014, 44–45).
For example, there may be a single “write” node which replicates to four “read” nodes that are used by the query functions. In more complex scenarios, nodes may be deployed to host only specific subsets of read data.
Considerations
Based on the points mentioned by Homer et al. (2014, 44):
-
Complexity raised by different write and read data stores: In most cases, the division of write and read data stores implies the use of an “eventual consistency” approach to transactions which increases an application’s design complexity.
-
CQRS is not a one-size fits all approach: CRUD and CQRS may co-exist. For example, CRUD may be used for trivial use-cases whereas the CQRS may be used for uses cases in which high scalability is the driving factor.
-
It is customary to implement CQRS using the Event Sourcing patern: It is likely that Homer et al. (2014) imply that simply wrapping CQRS functions on top of a conventional traditional SQL database is not necessary the preferable approach. Instead, CQRS is normally implemented alongside the Event Sourcing pattern (Homer et al. 2014, 50).
-
Collaborative versus simple domains: Homer et al. (2014, 45) suggest that the CQRS pattern is mainly applicable to complex collaborative domains in which multiple operations are performed in parallel on the same data and specific read and write optimisation may be required. The pattern may not be suitable in situations in which “the domain or the business rules are simple”.
We also have to note that the tuple-based approach used in this article’s example comes with a significant drawback: a single change to the logical entity handled by both the queries and commands results in several changes both on the provider and consumer sides.
Discussion and Conclusion
The problem identified by the CQRS pattern, embodied by the traditional CRUD/DTO approach to data handling, seems to be also relevant to a functional programming like Haskell when representing entities using the record syntax.
The “command” solution can be effectively implemented in Haskell using sum types which allows to perform multiple state changes in a single invocation. Arguably, queries may also be implemented in a “command” fashion so that it is not necessary to perform queries one-by-one:
1data OrderQuery =
2 OrderQuerySummarised OrderId
3 | OrderQueryFull OrderId
4 | OrderQueryLineItems OrderId
5 | OrderQueryItem ItemId
6 | OrderQueryByPrice Price
7 deriving (Show)
8
9data OrderQueryResult =
10 OrderQuerySummarisedResult (Name,Date,Total)
11 | OrderQueryFullResult (Name,Date,Total
12 ,[(ItemId,Description,Qty,Price)]
13 )
14 | OrderQueryLineItemsResult (ItemId,Description,Qty,Price)
15 | OrderQueryItemResult (Description,Qty,Price)
16 | OrderQueryByPriceResult [(OrderId,Name,Description)]
17 deriving (Show)
18
19queryOrder :: [OrderQuery] -> IO [OrderQueryResult]
The author’s final conclusion is that the CQRS pattern does not “replace” CRUD/DTO, but offers, instead, an alternative when scalability and complex update and query scenarios render said traditional pattern inappropriate.
Implementation
This article uses the minimum amount of Haskell syntax required to illustrate the CQRS model. It does not propose a concrete implementation. For actual implementations, refer to the following:
- CQRS Haskell Library by Bradur Arantsson
- CQRS/ES in Haskell by Sarunas Valaskevicius
- CQRS In Haskell by Yorick Laupa
Please also note that in this article we ignore Event Sourcing (ES) which is commonly used in conjunction with CQRS. The pattern is in fact many times referred to as CQRS/ES.
References
Fowler, Martin. 2005. “Event Sourcing.” December 12, 2005. http://martinfowler.com/eaaDev/EventSourcing.html.
Fowler, Martin. 2011. “CQRS.” July 14, 2011. http://martinfowler.com/bliki/CQRS.html.
Homer, Alex, John Sharp, Larry Brader, Masashi Narumoto, and Trent Swanson. 2014. Cloud Design Patterns: Prescriptive Architecture Guidance for Cloud Applications. Microsoft. https://msdn.microsoft.com/en-us/library/dn568099.aspx?f=255.
Young, Greg. 2010. “CQRS Documents.” November 2010. https://cqrs.files.wordpress.com/2010/11/cqrs_documents.pdf.